起因
昨天晚上看了「试当真」新出的一期 100 人综艺,早上起床的时候偶然开始回味这期节目。
以前只看过「试当真」拍的短片,一直以为这个频道是个小规模的团队。虽然听说过有古天乐这种大佬赞助,但是由于短片的镜头语言、剧本设计和拍摄手法都很专业,所以觉得这是个定位在先锋实验的拍摄团队。
这个综艺彻底颠覆了我对这个团队的想象。首先,这期综艺完全复制「鱿鱼游戏2」的形式,包括服饰道具乃至标题,所以肯定是拿到了版权的。其次这次拉来的 100 人,涵盖了香港 YouTube 界、歌手界、演员界、电台界,有大前辈,有完全不认识的新人,简直就是香港新一代综艺的标杆。
最后是这个综艺制作极其专业。参与人数多就不说了,还个个都是上得了舞台入得了镜头的表演型人格,现场可想而知的叽叽喳喳杂乱喧闹。但是成片出来观感却特别舒适,剪辑明快,镜头内说话的人口齿清晰,旁边的杂音对收音影响特别小。
回顾到这里,我突然产生了一个好奇。他们这么多人,声音是怎么录制,又是怎么剪辑到一块的?
先说录制的部分。无非就是两种办法,在定点的位置安置麦克风或者是每人身上都别一个麦克风。定点安置的缺点很明显,无法针对性地采集某个人的声音,会丧失后期剪辑的自由度。那么每个人都别一个麦克风,再配上定点麦克风收集场内的大声响应该就是录制方案的最优解了。
那么严峻的问题就来到了剪辑。一百多个麦克风意味着有一百多条音轨,这对剪辑来说简直是爆炸性的工作量。我曾经剪过一期自己录制的播客,对音频剪辑深有体会,它跟视频剪辑有很大的不同。视频能直接看到画面,并通过画面判断当前视频播放到哪里。但音频除了波形图外,没有任何可视化的内容,想要知道当前音频播放到哪里,需要重复播放前后的内容才能确定。
科幻一点来说,对视频的剪辑是在对「二维空间+时间」维度的剪辑,而对音频的剪辑是在对「一维空间+时间」维度的剪辑。而一维空间在时间切片上是完全没有特征的,就好比你听到一颗音,但你根本不可能只凭借这颗音找到它在这首曲子里的位置,要对其定位至少得把前前后后的音符都听上,才有可能定位它在乐曲里的位置。
我能想到更便捷一点的方法,是先将音轨和视频轨对齐,根据视频的内容定位再去剪辑音轨。在只有少数几条音轨的录制中,这样的工作量还算可以。但当音轨数达到几十上百时,工作量就十分爆炸了。第一步的工作自然是要在这众多的音轨中,找到与目前这个镜头相关的音轨。我询问了 AI 关于业内这部分相关的处理方法,发现解决方案还是十分简单粗暴的:分组。具体操作就是将每条轨道标准化命名,然后根据现场实际情况分组,剪辑时就能整组一起操作。
这是一个特解,在镜头固定和录音对象固定时是最优的。一旦这两者开始移动,对应的剪辑又开始繁琐起来。我搜索到的业内通用方式,也还是落后的打关键帧然后做调整。虽然现在也有 AI 辅助剪辑,但似乎还在起步阶段。
那有没有一种方法可以快速归类音轨呢?
灵光突然在这里闪过。
核心思想
我们要把音轨归类在一起,根本原因是,这些音轨是在一个我们所需要的相同的空间内产生的,它们有很强的空间属性。既然如此,我们只需要在录制声音的同时,将空间位置信息同步记录下来,问题就迎刃而解了。核心思想就是要将声音和位置绑定在一起。
当我拿着这个想法在中国国家知识产权系统上搜索时,发现了「滴滴」公司的一个专利「CN202310781549.8 一种录音设备和录音数据处理方法」。其中提到「基于时间对应性将录音数据和位置信息整合为录音文件存储至存储器中」、「可以在录制场地中收音时直接获取声音所在的位置,使得录音文件无需在后期制作过程中导入位置,即可在播放时能够还原录制场地的现场环境,提高了音频文件的制作效率。」
显然,「滴滴」的这个专利是想通过地理位置,直接定位当时网约车里的录音,用来对特殊路段的录音取证。虽然在背景技术里提到这是为了提高杜比声录制效果,但基于公司定位,我还是倾向于这个猜想。不管怎样,这个专利的想法还是与我的不谋而合了。
构建城堡
由于「滴滴」已经有了一个可以实现「将声音和位置绑定在一起」的专利,如果想要实现同样的功能,就需要思考别的途径。不过很巧妙的是,这个专利提出来的方法,是「将录音数据和位置信息整合为录音文件」,说明书里也不止一处提到「生成录音文件」、「更新录音文件」,这意味着这个专利是通过直接将位置信息写入录音文件中,以实现「将声音和位置绑定在一起」。但这样的做法反而束缚住了这个想法本身。
声音和位置完全没必要在生成阶段就绑定在一起。
继续拆解这个需求。由于录音音源必定来自某一个麦克风,声音和位置在这方面的绑定也就是一个标识而已。刨去这个标识,剩下的只有让两者在时间上同步。而声音本就是沿着时间线性生成的,所以这个需求的根本需求,就变成了生成一组沿着时间线性变化的位置。
顺理成章地,解决方案就出来了:构建一组附带时间码的位置信息。
这在硬件和软件上都不难实现。
硬件分析
网上随便找了一款 GPS 芯片 Beitian BN880,其最大刷新频率为 10Hz,空旷区域水平精度 2m。若是室内架设 UWB,随便找一款 UWB 芯片 DW1000,其参数则能做得更好,最大刷新率能轻松做到 100Hz 以上,最小精度甚至能达到 10cm。以综艺录制作为应用场景,人在普通行走的时候普遍速度在 2m/s 左右,就算是跑起来,普通人也是在 10m/s 左右,硬件的精度完全可以满足这样的移动。
功耗方面,GPS 芯片一个小时大概功率在 50mW,UWB 则更低,在 40uW 左右。作为对比,使用 96 kHz 采样率的录音设备功耗大概为 142mW,由此可见功耗的增加也不算太大,只是可能需要在散热以及信号方面做一些专门的设计。
软件分析
录音的功能与普通录音机区别不大,唯一的区别是需要额外生成一个文件,专门存放与时间码对应的地理定位信息。以我浅薄且快要忘却的单片机技术来考虑,也就是设一个定时器的事情。如果只是用于普通规格录制,精度不需要太高。若出现地理位置信息来不及采集的情况,也可以通过之前的位置信息和运动趋势推算出模拟位置,补全采样不足的数据。
之所以考虑是单独生成文件而不是直接附着在音频文件里,是为了拓展改造方便,原音频文件可以按原样使用。
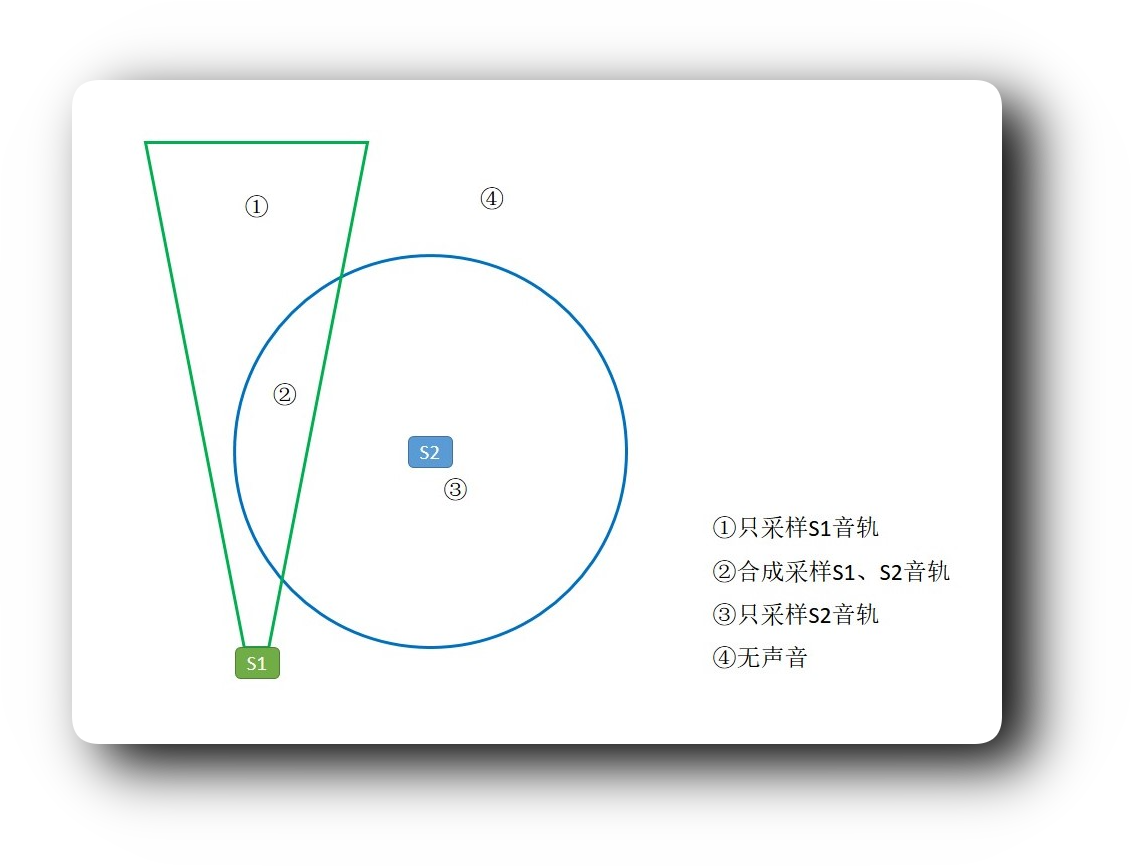
在后期处理时,只需要将两个文件根据时间码绑定在一起,就能得到一轨会随着播放时间改变物理位置的音频了。剪辑时可以设定将某个固定空间内存在的音频进行合成采样,又或者是跟随某个音频并以它为中心的某个空间内存在的音频进行合成采样。这样的处理方法,省去了逐条标记音轨,再逐条剪辑的麻烦,能以更符合感官直觉的方式进行高效剪辑。当然这一切都需要特定软件的支持。
树立飞桥
以上说的都是基础应用,而根据这些基础应用,其实可以拓展出更多东西。是的,这属于论文的「未来与展望」部分了。
空间音频
不同类型的麦克风,其收音的范围都不一样。全指向的麦克风收音范围可以模拟成一个以麦克风为中心的球体,枪式麦克风的收音范围则可以模拟成其朝向的长条形。还有其他诸如心形、双向等其他类型的麦克风。
现在我们可以获取麦克风所在的空间位置,假如能再获取麦克风自身的姿态,套上其包含范围、衰减等参数的收音模型,我们可以反向推导解算出空间中某一点能听到什么声音。收音模型可以通过类似视觉棋盘格标定的方式来标定搭建。这种推导解算理论上麦克风越多越精确。这个想法的构成和超声波雷达有点类似。但是不同的是,发声单元不是设备自身,而是实际发声物体。
现在的空间音频录制,有点类似于把麦克风绑在一个人的脑袋上,这个人听到什么,记录下来就是什么。在播放的时候,它的坐标点其实是和录制时是一致的,只能通过变化指向的姿态来体现出空间感。这更像是「被绑在凳子上」的空间音频。
如果搭配上前文所述的模型反向推导解算的算法,则可以实现「能到处走」的空间音频。因为这时录制的并不是「在某一个位置听到的声音」,而是在这一整片场景内,通过将所有麦克风收音范围的声音进行整合,解算出所有位置的发声源。这意味着在播放的时候,我们能够在虚拟空间内完全重建当时的声音环境,无论听众站着虚拟空间的哪个位置,都能通过类似于「光线追踪」的算法,来听到当时录制时对应位置能听到的声音。
利用这套东西,能给虚拟世界提供更加真实的体验。要类比的话,现在的空间音频是看普通的戏剧,而配合这套系统的空间音频则是看沉浸式戏剧。
由于我们还能获取麦克风自身的位置,所以理论上这套系统在运动的录音场景也能适用。但同步也会出现的问题是定位精度会进一步下降,以及运动产生的噪声也会被录制进去。
直觉镜头
这部分则跳脱出录音设备的范畴,覆盖到了整个视频制作流程了。
前文已经阐述过麦克风收音模型加上定位的方案了,如果将这套方案套在所有录制设备,包括摄影机、麦克风,那将会给视频制作流程带来极大的变化。
相对于麦克风收音范围的不可预见性,摄影机拍摄的画面范围是很明确的,视野范围和景深范围都是可以通过计算直接得出来的。因此,获取摄影机的取像模型是相当简单的事情,甚至这个模型的精度还特别高。
若是给摄影机也配上带时间码的位置信息,我们能很轻易地得知现在镜头内的画面包含空间中的哪些范围。而在空间音频部分的内容中,我们能反向推导解算出空间中某个位置能听到的声音。这两者关联起来,我们可以得出本应该正确出现在画面内的声音。
将关联的画面和声音直接剪辑在一起,我称这样生成出的视频片段为直觉镜头。因为它展现的是这个画面内真正会出现的声音,是符合物理直觉的。
有了各种带时间码的位置信息,直觉镜头的产生几乎不需要什么后期剪辑,它们在拍摄阶段就通过时空信息绑定在一起,后期只需耗费一点计算机算力,就能轻易自动地将它们重新绑定起来。
这时候回到文章开头的念头。在这个模式下,不需要一条条地去筛选音轨,也不需要逐条音轨剪辑,合适的声音本身就「长」在对应的画面里。剪辑师只需要编排好分镜,就完成了视频轨和音轨的剪辑。
当然,视频不是单靠画面拼贴剪辑就能完成的,还有调色、调音、特效等等的工序。带时间码的位置信息的独立性能保证其他工序照旧进行。
听起来这确实能缩减很大部分的工作量,但是这样的创新需要硬件端、软件端多家公司的配合升级才能实现。麦克风、相机厂商需要给它们的设备配置定位模块,视频剪辑软件需要升级定位匹配的功能。
所以最后这也只会是我一闪而过的灵光罢了。
